 The Myth of the Modular Monolith at Rails World. Photo by Aaron Patterson.
The Myth of the Modular Monolith at Rails World. Photo by Aaron Patterson.
Rails 5: ActionController::Parameters Now Returns an Object Instead of a Hash
A big change coming is how ActionController::Parameters works. ActionController::Parameters is where all of your params come from for your controllers. Calling params used to return a hash, but now will return an object.
Note: this doesn’t affect accessing the keys in the params hash like params[:id]. You can view the PR that implemented this change here: https://github.com/rails/rails/pull/20868
To access the parameters in the object you can add #to_h to the parameters:
params.to_hIf those params aren’t explictly permitted you will be returned a hash with only the permitted parameters. If none are permitted you’ll get an empy hash ({}). This comes in where you may be running #symbolize_keys or #slice on unpermitted params. If you’re accessing params that aren’t being saved to a model/db then you probably aren’t explictly permitting those parameters.
If we look at the #to_h method in ActionController::Parameters we can see it checks if the parameters are permitted before converting them to a hash.
# actionpack/lib/action_controller/metal/strong_parameters.rb
def to_h
if permitted?
@parameters.to_h
else
slice(*self.class.always_permitted_parameters).permit!.to_h
end
endLet’s take an example where we are slicing params to use later. If we have this method that slices params we used to be able to write:
def do_something_with_params
params.slice(:param_1, :param_2)
endWhich would return:
{ :param_1 => "a", :param_2 => "2" }But now that will return an ActionController::Parameters object.
Calling #to_h on this would return an empty hash because param_1 and param_2 aren’t permitted.
To get access to the params from ActionController::Parameters you need to first permit the params and then call #to_h on the object. The following returns the same thing as slice did previously.
def do_something_with_params
params.permit([:param_1, :param_2]).to_h
endAnother way to do this would be to use #to_unsafe_hash if you know the params are not user supplied and are safe:
def do_something_with_params
params.to_unsafe_h.slice(:param_1, :param_2)
endBy default controller and action parameters are allowed. To explicitly always allow other parameters you can set a configuration option in your application.rb that allows those parameters. Note: this will return the hash with string keys, not symbol keys.
Config option:
config.always_permitted_parameters = %w( controller action param_1 param_2 )Calling slice on the parameters:
def do_something_with_params
params.slice("param_1", "param_2").to_h
endIf you’re not sure when you’ll have time to upgrade it would be a good idea to write some tests for your controllers that access the params. That way when you do upgrade you’ll know to fix the params because your tests will be failing.
Website Redesign with Jekyll and Github Pages
Back in 2012 I built my first Rails app from scratch. It was a little blog that was meant as a learning tool and a way to contribute back to a community that gives so much to beginngers (gems, mentoring, etc).
I learned a lot from that blog, it helped me get jobs, and kept me accountable for the things I learned. It served as both a place to try new features and to record things I learned. It was where I built my first admin system, wrote about learning to build a forgot password form, everything.
But I realized I was neglecting it. I dreaded Rails security vulnerabilities, server vulnerabilities, and the chore that upgrading it to the next verison of Rails was going to be. It was also in desperate need of a design overhaul and didn’t look great on mobile browsers.
A few weeks ago I decided that I was tired of all of the above, and that my little blog had served it’s purpose well more than I had expected too. It helped me grow my career and myself.
Earlier today I swapped my blog to Github pages. I have to say I am very impressed with Jekyll even though I’ll miss my little Rails blog that I built from scratch. Jekyll is very powerful with great documentation. I was able to basically recreate my blog with the same URLs, RSS feed, and all. I have a front-end background so I was able to make my own theme quickly and easily.
The one caveat is that Github pages runs on a different version of Jekyll so some of the things in the documentation aren’t correct for that version. Once I figure that out though it was smooth sailing.
For posterity, here’s a picture of the old blog. I’m going to miss it.

Getting Your Local Environment Setup to Contribute to Rails
At RailsConf I’ll be leading a workshop on contributing to Ruby on Rails called “Breaking Down the Barrier: Demystifying Contributing to Rails”. My goal is to help you be confident in your ability to contribute to Rails. I’ll be focusing on contributing guidelines, advanced git commands, and traversing unfamiliar source code. I’ve allotted 90 minutes for the workshop so in order for you to get the most out of it you should have your system ready. In this post I’m going to go over the basics of getting set up.
Technically, the easiest way to get Rails running locally is to use the supplied VM. I prefer to have it running on my local machine, but if you’re using Windows I highly recommend using the VM. Although the VM is referred to the “easy way”, you likely already have 50% of the things you need installed on your system already if you’re actively developing Rails applications. If you do decide to use the VM you can skip these instructions. Please contact me on eileencodes to let me know if the VM directions are wrong. Or better yet, if you figure it out send a pull request!
Let’s get started with the basics of getting set up!
Ruby Manager
When working with Rails it’s likely you’ll be using a different Ruby version than you use in your production applications. It’s best to use Rails master with the most up-to-date version of Ruby. Currently, you can’t use Rails master / future Rails 5 without Ruby 2.2.2. You probably already have a way to have multiple rubies installed on your machine with either rbenv, rvm or chruby.
I personally use rbenv but I’ve used rvm in the past and hear good things about chruby. It really doesn’t matter which one you use as long as you can have multiple rubies installed on your machine.
Once you have that set up, install Ruby 2.2.1 2.2.2 (2.2.1 had a security vulnerability). Don’t forget if you have a new version of Ruby you’ll need to install bundler before you run bundle install on the Rails repo.
Fork & Clone Rails
Now we’ll get the Rails source code set up. First go to [github.com/rails/rails][rails-repo]{:target=”_blank”} and click “fork”. Some developers prefer to clone the main Rails repo and set up their fork as an upstream, but unless you have push rights to Rails (a commit bit) I don’t think this really makes sense. In my opinion having origin set as your repo works best so this guide is going to show you my preferred method.
Checkout your version of Rails to your local machine:
$ git clone git@github.com/your-fork/rails.git
You’ll need to get Rails master main repo as an upstream to your Rails. To do this simply run:
$ git remote add upstream https://github.com/rails/rails.git
Anytime you want to pull changes from Rails master into your master do:
$ git pull --rebase upstream master
$ git push origin masterHere you are pushing to your origin so your remote origin is always up-to-date with your master branch. Don’t work on your master branch and send PR’s from there. Always create a new branch. That way you can be working on multiple patches and your master is always clean and ready to checkout a new branch from. Pushing to your origin master also makes it easy to reset any of your branches to master without having to re-pull changes from upstream Rails.
Don’t forget to add a .ruby-version file to your Rails repo, but be sure not to check this in. I have a .gitignore_global file that sits in my home directory and ignores all .ruby-version files. Then you should run bundle install.
Databases
Ok now that you’ve got the Ruby and Rails source, you’ll need to get a few more things installed before you can start running Rails tests. And the most important of those things is databases!
It’s not really a requirement that you have ALL the databases installed but it’s a good idea to have the default databases that the Active Record supports; SQLite3, MySQL, and PostgreSQL. This will help you test the main adapters that are supported in Rails. It’s also a good idea if you’re working on any SQL specific parts of Active Record; you want to be sure you aren’t negatively changing the behavior of those other databases.
How you install databases is up to you. As a OS X user I install them with homebrew and follow the instructions output after installation. Remembering all the start/stop commands for databases is a pain though so I use LaunchRocket to control this. It’s a OS X preference pane to manage databases installed with homebrew. Additionally, you’ll need memcached for some ActionDispatch and ActionController tests.
Once you have the necessary databases installed you’ll need to create the databases and users required by the Rails tests.
MySQL
First create the users
$ mysql -uroot -p
mysql> CREATE USER 'rails'@'localhost';
mysql> GRANT ALL PRIVILEGES ON activerecord_unittest.*
to 'rails'@'localhost';
mysql> GRANT ALL PRIVILEGES ON activerecord_unittest2.*
to 'rails'@'localhost';
mysql> GRANT ALL PRIVILEGES ON inexistent_activerecord_unittest.*
to 'rails'@'localhost';Then create the databases
$ cd activerecord
$ bundle exec rake db:mysql:buildPostgreSQL
If you’re a Linux user create the user by running:
$ sudo -u postgres createuser --superuser $USER
If you’re an OS X user run:
$ createuser --superuser $USER
And then create the databases:
$ cd activerecord
$ bundle exec rake db:postgresql:buildCreating and Destroying
It’s also possible to create both MySQL and PostgresSQL databases at the same time by running:
$ cd activerecord
$ bundle exec rake db:createAnd you can destroy the databases and start over with:
$ cd activerecord
$ bundle exec rake db:dropRunning the Tests
Now that you have Ruby, the Rails source code, and the databases installed it’s time to run the tests. Now don’t just run rake test in the Rails root directory because you will be there all day waiting for railties tests to finish. Simply cd into the library you want to test and run:
$ rake test
To run Active Record tests, be sure to include the database adapter you want to test or else sqlite3, mysql, mysql2, and postgresql adapter tests will all run. To run tests for specific adapters do the following:
$ bundle exec rake test:sqlite3
$ bundle exec rake test:mysql
$ bundle exec rake test:mysql2
$ bundle exec rake test:postgresqlAnd don’t forget all these commands are available if you run rake -T in the directory you’re in.
See You at the Workshop
I’d tell you more about contributing to Rails but then I would have nothing to talk about at the workshop! I know it will be a lot of fun and you’ll learn tons. To read more about my workshop go to the RailsConf website.
If you have any issues at all getting set up ping me on twitter at eileencodes and I’ll do my best to point you in the right direction.
Survey: Tell Me About Your Experience in Open Source
I’ve started working on writing some new talks and developing an idea I have around open source contributions. Before I fully flesh out the idea I thought it would be beneficial to get the perspective of other developers about their experience in open source.
To help with this I’ve created three short surveys; one for project maintainers, one for contributors, and another for developers who have not yet contributed to open source. Answer as many questions as you like, all of them are optional. I promise not to use your name or other identifying information without your permission in any presentations that come out of these surveys.
Thank you for participating!
Survey for open source maintainers (contributors with push access/commit bits to projects count):
http://goo.gl/forms/e4jAeWo8T5
Survey for open source contributors:
http://goo.gl/forms/LjhUkG3A7k
Survey for developers who have yet to contribute to open source:
http://goo.gl/forms/ORTzLl4g7Y
Mountain West Ruby Conference Talk Video
My Mountain West Ruby Conference talk video is up! Thanks to Confreaks for the hard work to get these videos out!
Upgrading to Mavericks: When Everything Goes Horribly Wrong
I'm one of those curmudgeons that if it's not broken I don't want to fix it. I felt this way with upgrading from whatever Mac cat I was on to Mavericks and had put it off for a longggg time. Everyone said it would be easy and I should just do it. And I wondered if I was being lazy not going for it, so this weekend I took the plunge, which took several hours of convincing myself. The worst part was I started way too late, with a short 2-3 hour window before friends came over for dinner. The smart thing would have been to upgrade on Saturday morning.
I'm glad I put it off until I had real time to spend on it because it ended up not being smooth at all. Sure, I had a backup but when you're done upgrading and knee deep in fixing things, going backwards isn't too desirable. You have to make a choice to continue forging ahead or to turn back. When you're in the dark woods of an upgrade that went horribly wrong there's no way to know which path will be faster, so I chose to forge ahead.
What was broken?
Generally Mac applications worked fine, but I had to manually update and install command line tools for Xcode. This was kind of annoying to me because I feel like it should just be part of the upgrade. If a user has xcode and command line tools installed just update that along with everything else. I'm assuming if you're not a programmer your Mac upgrade probably went better than mine.
RVM and anything installed with homebrew was completely broken. It couldn't find any of those libraries or programs. I removed and reinstalled everything in homebrew; ack, mysql, postgresl, openssl, readline, etc. The biggest thing was after reinstalling these was the mysql and mysql2 gems needed to be uninstalled and rebundled because they were setup to use a different version of mysql.
 But as said many times before "always google first" - but make sure you're googling for the right thing. Thinking my problem was with rvm I was googling the errors I was geting and none of those posts said to fix homebrew first. Unfortunately it wasn't until I was going rogue uninstalling and reinstalling everything that I realized that most of my issues were with homebrew and could have been fixed simply by following this post.
But as said many times before "always google first" - but make sure you're googling for the right thing. Thinking my problem was with rvm I was googling the errors I was geting and none of those posts said to fix homebrew first. Unfortunately it wasn't until I was going rogue uninstalling and reinstalling everything that I realized that most of my issues were with homebrew and could have been fixed simply by following this post.
So if you have errors like "Libary not loaded: /path/to/openssl", "Libary not loaded: /path/to/mysql" etc, just follow the brew instructions in that post and your upgrade will probably go better than mine. If that doesn't fix it my recommendation would be to reinstall the libraries it's complaining about until it works. I also found that some rubies I needed to run rvm reinstall [ruby-version-number]
So if you do upgrade first backup, upgrade and fix homebrew before panicking. There are a couple nice things about Mavericks but so far I'm not impressed enough to be ok with fixing my dev environments.
Oddly no one I knew seemed to have these homebrew problems, so it could be some setting on my Mac? Hopefully though this will help someone else if they have issues with upgrading to Mavericks.
CRUD! What to do When Active Record, MySQL, and Your Data Betray You
On March 21st 2014 I gave my first conference talk at Mountain West Ruby. For the past year I have dealt with issues with Active Record that generally stemmed from a) that PhishMe has a LOT of data, and b) I didn't always understand how Active Record would translate into MySQL.
The slideshow is available on Speaker Deck.
The application discussed in this presentation is a real application and available on github.
For each of the fundamental CRUD functions; create, read, update, and delete, I'll demonstrate a problem I ran into with Active Record and the solution I came up with. My examples are based on an application that is an address book. The models and their relationships in an address book are easy to understand and explain. I didn't want to audience to get hung up on the application we were discussing.
In this address book application there is a User model. Users have many contacts and have many categories. Each contact belongs to a user and can have many categories through categorizations. Categories belong to a user and can have many contacts through categorizations. Contacts and categories are part of a many-to-many association and are connected through categorizations. Categorization belongs to a contact and belongs to a category for the join table.
Create
Imagine we have a CSV spreadsheet that we want to use to create our contacts. This spreadsheet has ten thousand rows. We could just run through each row of the CSV and insert each individual contact.
CSV.foreach("#{filepath}", headers: true) do |csv|
Contact.create!({
first_name: csv[0],
last_name: csv[1],
birthday: csv[2],
...
})
endThis will create the following SQL constructing an INSERT statement for each individual contact that needs to be added to the database.
INSERT INTO `contacts` (`first_name`, `last_name`, `birthday`,...) VALUES ('John', 'Smith', '1987-02-01',...);This INSERT statement will be run ten thousand times, which will take quite awhile. What if there was a way to insert more than one record at a time?
After a lot of research I found the quickest way was to use MySQL's Batch Insert. This method will speed up our creation of ten thousand records quite a bit. Now don't be scared but this means that we're getting our hands dirty with raw SQL. It's not often this happens in Rails but unfortunately there is no comparable method in Active Record so we are going to abandon it for this example.
Using the same spreadsheet of ten thousand contacts we'll create the records using MySQL Batch Insert.
contact_values = []
CSV.foreach("#{filepath}", headers: true) do |csv|
contact_values << "('#{csv[0]}','#{csv[1]}','#{csv[2]}'...)"
end
batch_size = 2000
while !contact_values.empty?
contacts_shifted = contact_values.shift(batch_size)
contacts_sql = "INSERT INTO contacts(first_name, last_name,
birthday,...)
VALUES#{contacts_shifted.join(", ")}"
ActiveRecord::Base.connection.execute(contacts_sql)
endFirst we'll read each row of the CSV and create an array of all of the values that need to be inserted into the database. Then we set a batch_size. This is really important because although MySQL can handle multiple contacts it can't handle all ten thousand being inserted at once. We'll end up blowing our MySQL innodb_buffer_pool_size or max_query_size if we're not careful. After a lot of trial and error I found 2k was a reliable setting for my servers, but you may have to experiment on your own.
Until we've inserted all of the contacts, the contact_values array is shifted by batch size. Shift removes the specified number of values from the front of the array and returns them. It does this until the contact values array is empty.
An SQL statement is then build with the attribute names and values to be inserted. We need to join the shifted contacts to complete the value list. Batch insert is made possible through the insert syntax by feeding it the values for each record that we want created. This can be quite tedious if you have a lot of columns because the columns names and values from the array must line up perfectly.
And finally we connect to the database and execute the INSERT statement. I'd like to note that this example assumes we have sanitized the input against SQL injection.
Batch insert creates the following MySQL query.
INSERT INTO contacts(first_name, last_name, birthday,...)
VALUES('Lauretta','Senger','1987-02-01',...), ('Jane','Roob','1987-02-01',...), ('Blaze','Lakin','1987-02-01',...),
('Elton','Cormier','1987-02-01',...),
('John','Kohler','1987-02-01',...),
('Clementine','Marvin','1987-02-01',...),
('Ova','Aufderhar','1987-02-01',...)
...It looks a lot similar to the other create statement, except it's chaining all the values instead of making a new INSERT statement for each contact. Let's take a look at how these queries benchmark.
When using the Benchmark module from the Ruby Standard Library the output represents user CPU time, system CPU time, the sum of user and system CPU and the elapsed real time. For my examples we're going to focus on the total time of user plus system.
For the example where we created each record individually it took 45.9 seconds in total time. That's a long time to wait for ten thousand records to be inserted into the database. MySQL Batch Insert took less than 3 seconds. That's a huge difference.
ActiveRecord Benchmark Data:
user system total real
=> 44.740000 1.180000 45.920000 ( 51.095556)
MySQL Batch Insert Benchmark Data:
user system total real
=> 2.710000 0.050000 2.760000 ( 3.227031)Benchmarking times may vary a little based on garbage collection, allocated memory, and the version of ruby and rails that you're using, but that does not change the fact that MySQL Batch Insert is drastically faster than creating and saving each individual record. But because we are not saving each record no callbacks will be fired. We're completely skipping the model and going straight to the database.
Read
Let's say we want to output the first name of each contact in the database. There are multiple ways to achieve the same result.
Reading Records with .each
We can run each on contacts and output the first name, but if we have a lot of records this is going to be quite costly to memory. A single SQL statement is run and all the records are collected at once.
Contact.where(user_id: 1, country: "USA").each do |contact|
puts contact.first_name
end
SELECT `contacts`.* FROM `contacts` WHERE
`contacts`.`user_id` = 1 AND `contacts`.`country` = 'USA'
=>
Lauretta
Shana
Jason
Jermain
Blaze
Jessy
Bradly
...Reading Records with .find_each
.find_each is a great way to save both time and memory. .find_each will collect our data in batches of 1000. Regardless of speed we want to be sure we are always using our server resources effectively and efficiently. .find_each helps us do that by running limited select statements so we don't blow our memory.
Contact.where(user_id: 1, country: "USA").find_each do |contact|
puts contact.first_name
end
SELECT `contacts`.* FROM `contacts` WHERE
`contacts`.`user_id` = 1 AND `contacts`.`country` = 'USA'
ORDER BY `contacts`.`id` ASC LIMIT 1000
=>
Lauretta
Shana
Jason
...
SELECT `contacts`.* FROM `contacts` WHERE `contacts`.`user_id`
= 1 AND `contacts`.`country` = 'USA' AND (`contacts`.`id` >
1001) ORDER BY `contacts`.`id` ASC LIMIT 1000
=> ...Reading Records with .pluck
Since we are only outputting the first_name of each contact we can use .pluck to get just that attribute. This is going to be much faster because this method creates an array of strings instead of returning objects. We only will have the first name attribute though and not the rest of the record.
Contact.where(user_id: 1, country: "USA")
.pluck(:first_name).each do |first_name|
puts first_name
end
SELECT `contacts`.`first_name` FROM `contacts` WHERE `contacts`.`user_id` = 1 AND `contacts`.`country` = 'USA'
=> ["Lauretta", "Shana", "Jason", "Jermain", "Blaze", "Jessy", "Bradly", "Emma", "Cruz", "Elton", "Dashawn", "Rosanna", "Ryan", "Leonel", "Ashly", "Mittie", "Tobin", "Antonio", "Chad", "Lauryn", "Sydnie", "Sebastian", "Johnpaul", "Yasmeen", "Junior", "Monroe", "Avery",...]So which one was fastest?
.each Benchmark Data:
user system total real
=> 0.950000 0.060000 1.010000 ( 1.050266)
.find_each Benchmark Data:
user system total real
=> 0.900000 0.040000 0.940000 ( 0.976979)
.pluck Benchmark Data:
user system total real
=> 0.080000 0.020000 0.100000 ( 0.126814).each benchmarked at 1 second. .find_each was not much faster but again with collecting records we're more concerned with memory than time. 10k records won't hurt our memory much but 100k will have much more of an impact. With pluck we can see a lot of time is saved. It's a lot faster than .each or .find_each since we are only collecting the records first name.
I understand you may not be impressed with these numbers but what would these benchmarks look like if we had 100k records?
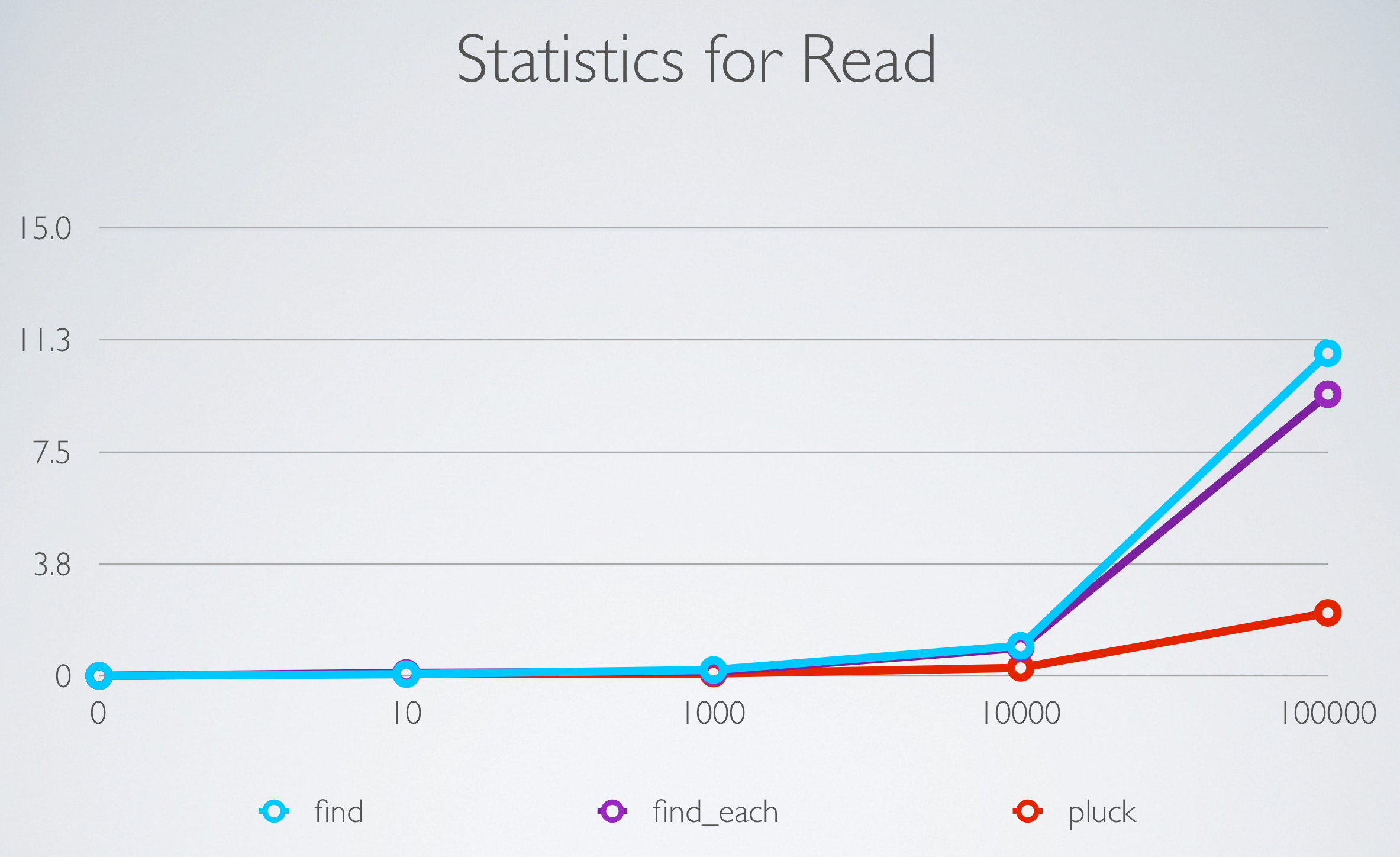
Here we can see when the dataset increases from 10k to 100k records the length of time queries take increases quite a bit and the savings are more obvious. On the y axis we have the number of seconds and the x axis represents the number of records. For 100k records .each in blue takes almost 11 seconds, .find_each in purple takes 9.43 and in red is the fastest at 2.11 seconds.
Another interesting method that Active Records provides is .find_by_sql. This method allows us to craft custom SQL queries. At times when writing our queries this may be faster and more efficient because Active Record doesn't always know the best way to get the data we're looking for. We can compare dates or optimized queries for performance with .find_by_sql.
Contact.find_by_sql([
"SELECT first_name FROM contacts WHERE
user_id=? AND
country=? AND birthday > ?",
1, 'USA','1987-01-01'
]).each do |contact|
puts contact.first_name
endUpdate
Let's say we wanted to change all of our categorizations from the "Coworkers" category to the "Networking" category. In this query we are collecting all the records and updating the category_id attribute on each one using update_attributes. We are instantiating and updating each individual record for all ten thousand.
category = Category.where(name: "Networking").first
Categorization.all.each do |categorization|
categorization.update_attributes(category_id: category.id)
endThis produces the following SQL, constructing an UPDATE statement for all ten thousand records.
UPDATE `categorizations` SET `category_id` = 1 WHERE `categorizations`.`id` = 1
UPDATE `categorizations` SET `category_id` = 1 WHERE `categorizations`.`id` = 2
UPDATE `categorizations` SET `category_id` = 1 WHERE `categorizations`.`id` = 3
UPDATE `categorizations` SET `category_id` = 1 WHERE `categorizations`.`id` = 4
UPDATE `categorizations` SET `category_id` = 1 WHERE `categorizations`.`id` = 5
UPDATE `categorizations` SET `category_id` = 1 WHERE `categorizations`.`id` = 6
...A better and faster way to update all the contacts categories from the "Coworkers" category to the "Networking" category would be to use update_all.
category = Category.where(name: "Networking").first
Categorization.update_all(category_id: category.id)This method creates a single SQL UPDATE statement. Records are not instantiated and are all updated at once without running save on each record. Again since we are not saving individual objects, callbacks will not be fired.
UPDATE `categorizations` SET `categorizations`.`category_id` = 1
Benchmark Data
The first query where we update each individual record one at a time takes almost 14 seconds. That's not too long but we can do better. .update_all is so fast for ten thousand records that it barely registers as taking any time at all. That's incredible savings we're seeing here.
update_attributes Benchmark Data:
user system total real
=> 12.990000 0.870000 13.860000 ( 17.156265)
update_all Benchmark Data:
user system total real
=> 0.000000 0.000000 0.000000 ( 0.042140)Delete
To talk about delete we first need to discuss the differences between delete_all, destroy_all and how setting a dependency on a has_many association affect their outcome.
Contact.destroy_all with a dependency set
In cases where we are deleting a model through destroy_all AND the dependency is set to delete_all or destroy the Contact and all associated categorizations will be removed. destroy_all on Contact will remove contacts individually and fire callbacks when a dependency is specified. From the SQL you can see the associated categorization is selected, removed, and then the parent contact is then deleted. It will do this individually for all ten thousand contacts and all associated categorizations in the database.
# model relationships
Contact
has_many :categorizations, dependent: :destroy
has_many :categories, through: :categorizations
Category
has_many :categorizations, dependent: :destroy
has_many :contacts, through: :categorizations
# query run
Contact.destroy_all
# sql produced
SELECT `categorizations`.* FROM `categorizations` WHERE `categorizations`.`contact_id` = 1
DELETE FROM `categorizations` WHERE `categorizations`.`id` = 1
DELETE FROM `contacts` WHERE `contacts`.`id` = 1Contact.delete_all with a dependency set
If we instead run delete_all on Contact only those contacts will be removed, regardless if the dependency is set to delete_all or destroy. The following SQL statement will be produced. No categorizations will be removed when using a delete_all on contacts. delete_all will not destroy individual contact and will not fire callbacks when run on a parent model. All contacts are removed at once.
# model relationships
Contact
has_many :categorizations, dependent: :delete_all
has_many :categories, through: :categorizations
Category
has_many :categorizations, dependent: :delete_all
has_many :contacts, through: :categorizations
# query run
Contact.delete_all
# sql produced
DELETE FROM `contacts`Contact.delete_all with no dependency set
If no dependency is set the delete_all and destroy_all both ignore the related categorizations and only remove the contacts. The difference is in how they remove those contacts. delete_all removes them all at once with the exact same SQL statement demonstrated earlier. It ignores the categorizations as it did before.
# model relationships
Contact
has_many :categorizations
has_many :categories, through: :categorizations
Category
has_many :categorizations
has_many :contacts, through: :categorizations
# query run
Contact.delete_all
# sql produced
DELETE FROM `contacts`Contact.destroy_all with no dependency set
destroy_all without a dependency removes each contact individually, but not categorizations. This is because no dependency is specified.
# model relationships
Contact
has_many :categorizations
has_many :categories, through: :categorizations
Category
has_many :categorizations
has_many :contacts, through: :categorizations
# query run
Contact.destroy_all
# sql produced
DELETE FROM `contacts` WHERE `contacts`.`id` = 1
DELETE FROM `contacts` WHERE `contacts`.`id` = 2
DELETE FROM `contacts` WHERE `contacts`.`id` = 3
...Deleting Associated Records Through a Parent Record
It's important to keep these details in mind when setting up how our models are associated. These dependencies can have some interesting side effects when delete_all or destroy are run on associated records through a parent model.
What if we wanted to run a query like category.contacts.destroy_all. Regardless of the dependencies this code has a big problem. When run this won't delete the contacts that are related to the category because category does NOT own contacts. The only way category knows about contacts is through categorizations. Therefore, this code is only going to delete the associated categorizations and not the contacts.
We should change that to be more clear. No one has their model associations memorized, and many developers will think the contacts are being deleted, not the contacts. So let's write category.categorizations.destroy_all
Unfortunately destroy_all is going to be slow. We're not deleting category so we aren't going to gain anything from the destroy_all callbacks. I want to just the delete the categorizations. Let's instead run category.categorizations.delete_all.
The relationships between category and categorizations is called a CollectionProxy. The Rails docs describe a CollectionProxy as the middleman between the object that holds the association - in our case the category - and the associated object - the categorizations. Let's take a look at how dependency settings on a has_many association affect deleting records through a CollectionProxy.
If we run category.categorization.delete_all and have no dependency set, instead of removing the categorization the category_id in those records will be set to null. This is because the default dependency setting on a CollectionProxy is to nullify. The records will be left in the database instead of being removed. We can see an update statement is run setting the categorizations category id to null instead of removing the record.
# model relationships
Contact
has_many :categorizations
has_many :categories, through: :categorizations
Category
has_many :categorizations
has_many :contacts, through: :categorizations
# query run
category.categorizations.delete_all
# sql produced
UPDATE `categorizations` SET `categorizations`.`category_id` = NULL WHERE `categorizations`.`category_id` = 1What if we set the dependency option to destroy? Well in that case each record would be instantiated and deleted individually. If that is what we wanted we would have just used destroy_all instead of delete_all. Generally when using delete_all we want the records to be deleted at once and not fire callbacks because we're trying to save time and memory. We don't want to wait for individual object to be removed. It defeats the purpose of using delete_all in the first place.
# model relationships
Contact
has_many :categorizations, dependent: :destroy
has_many :categories, through: :categorizations
Category
has_many :categorizations, dependent: :destroy
has_many :contacts, through: :categorizations
# query run
category.categorizations.delete_all
# sql produced
DELETE FROM `categorizations` WHERE `categorizations`.`id` = 1
DELETE FROM `categorizations` WHERE `categorizations`.`id` = 2
DELETE FROM `categorizations` WHERE `categorizations`.`id` = 3
DELETE FROM `categorizations` WHERE `categorizations`.`id` = 4
...Alright, so what happens if we set the dependency to delete_all? It should be fast and efficient, right? This query takes 130 seconds. 130 seconds. Why? What's going on here?
category.categorizations.delete_all
user system total real
=> 130.080000 0.120000 130.200000 (130.308334)I expected the SQL statement to be DELETE FROM `categorizations` WHERE `categorizations`.`category_id` = 1 but instead I got:
DELETE FROM `categorizations` WHERE `categorizations`.`category_id` = 1 AND
`categorizations`.`id` IN (1, 2, 3, 4, 5, 6, 7, 8, 9,
10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22,
23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46...10000)This is because when deleting a CollectionProxy with a delete_all dependency setting, the query returns an array of all records that have been removed. Because it needs to collect all the objects and return them, this ends up making the query very slow. This is definitely not from delete_all, and this isn't really fast. So how do we fix this problem?
There's an easy and clear way to solve this. I find deleting records through an association to be risky and complicated. We already know what we want to delete so we can collect the categorizations through the category ID and delete them directly. The code is super clear, concise and benchmarks at remarkable speed for 10k records. It even produces the super simple delete statement we were expecting earlier.
# get the category
category = Category.where(name: "Networking").first
# find categorizations by category ID and delete directly
Categorization.where(category_id: category.id).delete_all
# benchmark data
user system total real
=> 0.010000 0.000000 0.010000 ( 0.014286)
# sql produced
DELETE FROM `categorizations` WHERE `categorizations`.`category_id` = 1Conclusion: What Have We Learned?
- Active Record is a great tool, but we shouldn't let it's magical properties make us lazy.
- Our assumptions about Active Record can have major consequences if we aren't paying close attention to how our queries are being translated into sequel. This is especially try for large datasets.
- We can overcome most problems with Active Record by changing what we're asking it to do, and being more aware of the consequences of the code that we write.
- There are some really great tools out there to help you profile your queries and memory usage.
- New Relic can help identify places where we might have slow SQL queries that are consuming our memory.
- MiniProfile adds a badge to your application that records query times form the database.
- And the Bullet gem identifies N+1 queries and let's you know when you should add eager loading
I hope you enjoyed this post and the related slideshow!
Just Use `ack`
I spent a good portion of yesterday obsessing over my grep colors. They worked fine on my VM (Ubuntu) but not on my mac. I then figured out that mac is FreeBSD and Linux grep is GNU. So the export GREP_COLORS='1;32' just isn't going to work.
I then spent too much time trying to get that to work when all the Stackoverflow sources said just use ack. So I gave in and installed it because I was tired of doing it "the hard way".
It's amazing. I know most of you probably already use ack. If you don't you are "doing it wrong" as I have been for some time. Now stop wasting time reading this and go download it.
Installation instructions here.
Colors and line numbers are on by default! Yay! To change the colors simple add this to your .bash_profile or whatever your preference:
alias ack='ack --color-filename="red bold" --color-match="yellow bold" --color-lineno=white'You're welcome.
MySQL Batch Create's Awesomeness
Awhile back I had to insert tons of data into a MySQL database. The app had already been built and using a different database was not an option. The dataset I was creating was massive. I needed to create 100k or more records.
I attempted to do this with a nice clean ActiveRecord statement:
100000.times do |record|
Record.create!({
attribute_1: "attribute 1",
attribute_2: "attribute 2",
...
attribute_20: "attribute_20"
})
endThe results were not pretty. Although I didn't hit any timeouts, the query was taking HOURS - and likely would have timed out on a server that had less memory than my VM. This was not going to work because this was just one part of a module I was writing that needed to run.
I spent a lot of time researching creating lots of records at once and decided there was only one conclusion — the solution was MySQL batch insert. Note: this method will not work if you have complicated callbacks that need to run after each record is created. Here's how I handled the situation:
# setup the array to hold the values for the batch insert
record_values = []
# for this case we will pretend we have an array that needs to be sorted into readable data
record_data.each do |record|
record_values << "('#{record.something}','#{record.something_else}','#{Time.now}'...'#{record.attribute_20})"
end
# set the number of records you want MySQL to handle at once. Too many records and MySQL will run out of memory
batch_size = 20000
# create a while loop to batch insert the records
while !record_values.empty?
# use shift to move down the array based on batch size
record_values_shitfted = record_values.shift(batch_size)
# create the required sql string
record_values_sql = "INSERT INTO records(attribute_1, attribute_2, attribute_3...attribute_20) VALUES#{record_values_shifted.join(", ")}"
# execute sql
ActiveRecord::Base.connection.execute(record_values_sql)
endThis was infinitely faster than ActiveRecord could be and unfortunately it doesn't have a way to do a batch insert. Sometimes straight up MySQL is faster and better than ActiveRecord.
Forwarding Domains with Nginx
Recently I decided to switch the url of this blog from eileenbuildswithrails.com to eileencodes.com. If you're curious about why I changed the name read this post.
With this change I wanted to keep eileenbuildswithrails.com, but forward it to eileencodes.com. Since nginx handles domain names based on alphabetical order the default domain was not forwarding correctly. The key is to forward the domains in the config files themselves.
Setting up the redirect in nginx is really easy once you know how to do it. Simply set up two server definitions; one to forward the old domain to the new domain, and one to handle rewrite of the new domain to www. And that's it. See below:
server {
listen 80;
server_name olddomain.com www.olddomain.com;
rewrite ^(.*) http://www.newdomain.com$request_uri permanent;
}
server {
listen 80;
server_name newdomain.com;
rewrite ^ http://www.newdomain.com$request_uri permanent;
}